|
▼ このページでは、パソコン ( PC ) 用、及びスマートフォン・タブレットPC用CPU , 組込みMPU関係の情報について掲示しております。近年マイクロプロセッサの市場では競争がそれぞれメーカで激化していると思われます。
種々のコア・人工知能TinyML-RunTimeベンチマークはこちらのページです。
For-Loopベンチマークはこちらのページです。
激安のRISC-Vコアボードが魅力的、RISC-V関係はこちらのページです。
Multi-Threadベンチマークはこちらのページです。 更新 2025.06.08
超低消費電力なMPU関係はこちらのページです。 更新 2024.03.18
旧マイクロ・プロセッサ関係のページはこちらです。
◆ ARM関係のコアが多い中、他のコアも・・・ 2020.07.26
近年、ARMコア以外のデバイス・メーカーがARMコアのMPUやMCUのデバイスを製造するようになっており、ARMコアを利用するメリットが大きいとは思えない。
MCUのデバイスは単にCPUコアが全て同様となければよい訳ではなく、むしろ、周辺のインターフェースが充実しているほうが低コストの製品を開発できるメリットがある。
今時、CPUコアのチップに多数の周辺回路チップ・デバイスで構成するなどの製品では他メーカーの競争で埋没してしまうであろう。
中国製の低価格なRISC-VコアとAIのNPUをワンチップ・デバイスがあり、利用するかどうか悩ましい。中国製のMCUには周辺回路が貧弱であり、組み込み関係では利用価値が低い。
◆ 古典的なノイマン型コンピュータの限界 2018.12.02
最近、高性能なCPUチツプは微細化加工技術も限界に達しているようであり、そのプロセス加工技術が数ナノメートル(nm)となっいるが性能が格段向上していない、マルチ・コア技術が向上したが劇的な性能向上と低消費電力なプロセッサ・チツプになっていない。
近年、量子コンピュータ・チップや人口知能チップが注目されている。
◆ 汎用CPU意味の無いベンチマークテスト 2014.11.02
近年、高性能なマルチコアのCPUやGPUが多くなり、スマホやタブレットPCは格段に性能が向上し、ディスクトップPC用のCPUに迫る勢いである。
クアッド・コアのスマフォやタブレットPCは業務関係での利用でなければ,ネット関係での利用でノートPCが不要とも言える。重たい画像処理アプリも軽快に動作してしまう,技術の進歩も素晴らしい。
CPUのベンチマーク・テスト結果
◆ 汎用CPUよりもGPGPUが高性能 2010.06.18
最近の高性能なGPGPUの話題と多くなっている。性能的には汎用のIntel系CPUも限界か・・・、古いアーキテクチァーの汎用CPUのSSE処理よりもGPGPUのほうが高性能である。計算処理はCore 2 Duo よりもGPGPUのほうが数十倍~数百倍高性能とのベッチマーク結果が公開されている。また、ARMデュアル・コアとGPGPUコアとのワンチップCPUが製品化されており、その8コアのTegra 2は 1GHz で約0.5Wと低消費電力であり、Intel系Atom よりも数十倍以上高性能と言う情報もある。実際、Atom搭載のWindows PC を使用すると明らかに遅い、画面の表示にもたつきが感じられる。Tegra 2 を搭載したAndroidタブレットPCが発表されている。遂に、インテル社の独占状態も終わりか・・・。
◆ CPU &MPU レイトレーシング(RayTrace)ベンチマーク 2020.10.03作成、 2026.02.13 更新
近年のPCやスマホ、組み込み用プロセッサはマルチコアが常識となり、そのコア数が24コアもある。組み込み関係のMCUでもDual Coreが増えておりトリプル・コアやCore x4~32個 のMCUもある。下記にMPU & MCUのRayTracingベンチマーク性能を比較した。
RX62T 1.8" TFT LCD ->   <- RX231 LCD <- RX231 LCD
Raspberry Pi 5 & Orange Pi Zero2 レイトレーシング表示 2024.04.02
RasPi 5  Orange Pi Zero2 Orange Pi Zero2 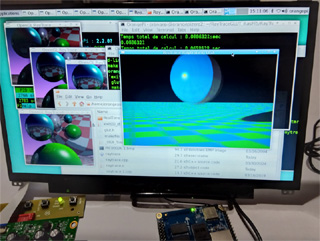
タブレット & スマホ・レイトレーシング320 x 240ピクセル表示
スマホ  タブレット タブレット 
スマホとタブレットのアニメーション・Raytracer、1個の球体で最大200fps表示、GPU計算なし CPUのみでも高性能。
下記のベンチマークはノンアニメーションの静止画像
| MPU & MCU |
クロック |
解像度 |
ベンチマーク |
備 考 |
| RX62T (RXv1) |
96MHz |
160x120 |
1.3 sec.(g++ -O2) |
SPI 24MHz, 1.8 "TFT |
| RX231 (RXv2) ※-3 |
48MHz |
160x120 |
1.71 sec.《0.49s》(g++ -O2) |
SPI 6MHz, 1.8 "TFT |
| RX231 (RXv2) ※-1 |
48MHz |
240x240 |
2.3 sec.《1.2s》(g++ -O2) |
SPI 6MHz, 1.3 "TFT |
| STM32F4(Cortex-M4) |
72MHz |
320x240 |
52 sec.(他サイト) |
SPI Type TFT LCD |
| ESP32 |
160MHz |
320x240 |
13 sec.(他サイト) |
SPI Type TFT LCD |
| ESP8266 |
160MHz |
320x240 |
33 sec.(他サイト) |
SPI Type TFT LCD |
| ESP32C3 ※-9 |
160MHz |
320x240 |
28 sec. |
計算処理のみ Arduino-cli |
| RP2040 |
133MHz |
320x240 |
24 sec. |
計算処理のみ Arduino-cli |
| RP2350(M33) ※-9 |
150MHz |
320x240 |
2.43 sec. |
計算処理のみ Arduino-cli |
| RX71M (RXv2) |
240MHz |
320x240 |
0.4 sec.(g++ -O2) |
計算処理のみ |
| RX72T (RXv3) |
192MHz |
320x240 |
0.99 sec.(g++ -O2) ※-10 |
8bits-Bus TFT-LCD |
| RX72T (RXv3) |
192MHz |
320x240 |
0.33 sec.(g++ -O2) |
計算処理のみ |
| ATmega |
16MHz |
320x240 |
290 sec.(他サイト) |
SPI Type TFT LCD |
| LicheePi Nano (ARM926EJ) |
720MHz |
320x240 |
2.14 sec. ※-9 |
LCD LVDS タイプ |
| LicheePi Nano |
720MHz |
800x480 |
10.28 sec. |
LCD LVDS タイプ |
| C906 (RV64GCV) ※-2 |
1.0GHz |
320x240 |
0.12 sec.(gcc -O2) |
計算処理のみ |
| Milk-V Duo C906 ※-4 |
1.0GHz |
320x240 |
0.16 sec.(g++ -O2) |
計算処理のみ 100回/16.0s |
| ARM Cortex-A7x4 ( ARMv7) |
1.0GHz |
320x240 |
0.32 sec.(gcc -O3) |
Android 4.2タブレット |
| ARM Cortex-A7x4 ( ARMv7) |
1.2GHz |
320x240 |
0.25 sec.(gcc -O3) |
Android 5.0タブレット |
| ARM Cortex-A7x4 ( ARMv7) |
1.2GHz |
320x240 |
0.23 sec.(gcc -O3) |
計算処理のみ |
| Cortex-A73x4, A53x4 ( ARMv8) |
2.0GHz |
320x240 |
0.08 sec.(gcc -O3) |
Android 9.0タブレット |
| Cortex-A53x4 ( ARMv8) |
2.0GHz |
320x240 |
0.14 sec.(gcc -O3) |
Android 9.0タブレット |
| Cortex-A55x8 ( ARMv8) |
1.8GHz |
320x240 |
0.15 sec.(gcc -O3) |
Android 13タブレット |
| Cortex-A76x2, A55x6 ( ARMv8) |
2.6GHz |
320x240 |
0.042 sec.(gcc -O3) |
Android 10 スマホ |
| Cortex-A76x2, A55x6 ( ARMv8) |
2.6GHz |
320x240 |
21ms --> 6ms ※-5 |
Multi-Thread計算処理のみ |
| Cortex-A78x2, A55x6 ( ARMv8) |
2.2GHz |
320x240 |
0.040 sec.(gcc -O3) |
Android 12 スマホ |
| Cortex-A75x1, A55x3 ( ARMv8) |
2.2GHz |
320x240 |
0.062 sec.(gcc -O3) |
Android 11 スマホ |
| Cortex-A75x1, A55x3( ARMv8) |
2.0GHz |
320x240 |
29ms --> 6.6ms ※-6 |
Multi-Thread計算処理のみ |
| RasPi-5 Cortex-A76x4 ( ARMv8) |
2.4GHz |
320x240 |
17ms --> 5.5ms ※-7 |
Multi-Thread計算処理のみ |
| Orange Pi RV2 RV64GCV x 8 |
1.6GHz |
800x600 |
2.69s --> 3.4ms ※-8 |
Vec+Multi-Thread計算処理のみ |
| Celeron N3050 Dual (2016) |
1.6GHz |
320x240 |
0.065 sec.(g++ -O3, gcc-11) |
計算処理のみ Ubuntu22.04 |
| iMac Intel Core2 Duo (2009) |
2.8GHz |
320x240 |
0.08 sec.(g++ -O3) |
GUI GLUT |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
320x240 |
0.08 sec.(g++ -O3) |
GUI GLUT |
| iMac Intel Core2 Duo |
2.8GHz |
800x600 |
0.8 sec.(g++ -O2) |
OSX-10.6 & 10.8 |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
320x240 |
0.08 sec.(C++)50回/4sec. |
OSX-10.9 GLUT |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
320x240 |
26ms --> 8ms ※-5 |
Multi-Thread計算処理のみ |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
400x300 |
28.6 sec.(Python-3.7) |
numpy最適化なし |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
400x300 |
0.45 sec. 2FPS(Python-3.7) |
numpy最適化あり |
| PC |
? GHz |
800x600 |
83 sec.(Python) |
他サイトから引用 |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
800x800 |
98 sec.(Python-3.7) |
numpy最適化なし |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
800x800 |
1.2 sec.(Python-3.7) |
numpy最適化あり |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
512x512 |
33.4 sec.(Python-3.7) |
numpy最適化なし |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
512x512 |
0.45 sec. 2FPs(Python-3.7) |
numpy最適化あり |
※-5~8 計測値 シングル・スレッド --> マルチ・スレッド
※-8 ベクトル + マルチスレッド、そのページはこちらです。
※-1, ※-3 RX231はSPI通信関係を最適化した結果、48MHz動作で240x240ピクセル/2.3sec.とRX62Tより良い結果となった。2023.01.16 更新2023.11.03
ルネサス社はRX231の演算処理性能を向上させたと発表しており、演算処理のみで240x240ピクセル1.2秒と48MHzの低クロックとしては高性能だ。2023.01.16 更新2023.11.03
注 ): 上記の※-5以外は全てベッチマーク・テストはコア1個の性能、マルチスレッドやOpenMP, SIMDの最適化なし。
※-8 Orange Pi RV2 はベクトル演算 + マルチ・スレッド(Multi-Thread)処理により最適化すれば、驚きの性能アップとなった。Core i5 Quad 2.8GHz よりも高性能です。Python + Numpy よりも約340倍高性能、スパコンでも利用されているベクトル演算は凄い。 2025.05.02
※-5 マルチ・スレッド(Multi-Thread)処理により最適化すれば、Octaコアで6~7倍程度の性能向上となる。しかし、Multi-ThreadとSIMD計算処理を同時に最適化しなければならず難易度が高い。そのページはこちら(Raytrace含む)です。更新 2024.12.25
Multi-Thread RayTracing ->  
※-6 マルチ・スレッド(Multi-Thread)処理により最適化すれば、Quadコアで3倍程度の性能向上となる。格安な中国製Android 10インチタブレットBAMX I10 Proは8,400円程度購入できた。BAMX I10 ProのSoCがUnisoc T310でありCortex-A75 2.0GHz Quadコアでも充分な性能です。 UnisocのSoCにはT606や T616, T618等がありプロセス製造が12nmであり、その販売価格が12,990円程度から購入が可能。 2024.02.04
※-2 低消費電力なLichee RV 64GCV(C906)は演算計算処理のみで120msとARMコア 1.0GHzと同等な性能であった。最新のgcc/g++コンパイラーを使用しMilk-V Duo のようにベクトル計算処理を最適化すれば約4倍性能アップとなる。作成 2024.08.03 訂正 2025.03.19
※-4 低価格なMilk-V Duo(C906コア)は1,000円以下であり低速なESP32やラズパイ・ピコRaspberry Pi Pico(Cortex-M0+)等を利用するよりも遥かに高性能です。
Ras Pi Pico-2はキャシュ・メモリ16kB/16kBと小さくベクトル実行ユニットがないが、C906コアにはL1キャシュの I-Cache 32kBと D-Cache 64kBありベクトル実行ユニットもあり優位性がある。無茶なオーバークロック動作をやる必要性がなく安心して使用できる。
100回の計算処理で16.0秒(1回換算値0.16s)であり、計算処理性能がよい。コンパイルした実行コードを確認した結果、ARM系SIMD命令のFMAコードと同様なFMA実行コードが生成されておりベクトル実行ユニットの性能がよい。RISC-V系のgcc/g++コンパイラーの最適化が進んでおりgcc/g++コンパイラーは最新版を利用した方がよい。作成 2024.08.03 訂正 2026.02.13
※-7 Raspberry Pi 5が販売され話題となっており、Cortex-A76 2.4GHz Quadコア、プロセス製造が16nmであり、消費電力が約10Wと低消費電力ではなくCPUコア温度が85℃程度と冷却ファンが必須であり、最悪なことはAC/DCアダプターDC5.1V/5A(27W)が必要であり、販売価格も16,000円以上、7~10インチのタッチパネルLCDが必要でありトータルで3万円弱となり低価格とは言えない。 2024.02.04
※-7 ラズパイ-5のボード電源消費電流を測定した結果、起動時1.1A、ベンチマーク時0.7~0.8A(約4.1W)であった。AC/DCアダプターDC5.1V/5A(27W)はSSD記憶媒体やUSBに複数個の500mA以上の機器を接続しなければ、DC5.1V/2A(約10W)で問題ない。RasPi-5の販売価格が1万円程度となり利用価値がある、但し、夏場の室温30℃以上では冷却ファンが必要となることが残念。 2024.03.17
RasPi 5での Ubuntu 23.10利用はこちらのページです。
※-9 ESP32C3には FPU 機能がない為、浮動小数点演算をソフト側で計算処理が必要となり遅くなっている。その点、ESP32P4 / 400MHz は Coremark 計算処理が早いようです。Ras Pi Pico2(RP2350)は FPU を実装しており計算性能が良い。作成 2025.10.05
近年、低価格の台湾製や中国製のRISC-V系等のSoCが高クロック200~600MHzとなっており、高クロックが高性能とも言えない。低クロックなRX231のSPI通信処理を最適化した結果、240x240ピクセル塗り潰しが7フレーム/秒(7FPs)と格段に性能がアップした。次期、RXv4は7ステージで300MHz台となるのかルネサス社に期待したい。2023.01.16
PythonはNumpyラブラリーを利用しなければ計算処理が遅い、ベクトル演算処理で最適化すれば大幅に処理時間が短縮できる。それでも、C++以上とはならない。 2022.02.15
V3s DE->TCON->RGB-LCD  320 x 240ピクセル表示 320 x 240ピクセル表示
激安LicheePi Zero(Allwinner V3s A7コア)ボードにRGB-LCD(800 x 480 dots )を接続し、DE->TCON->RGB-LCDのベアメタル・プログラミングでレイトレーシング・実行コードを試したが残念なことに320 x 240ピクセル表示で約2.5秒と遅い。その原因を突き詰めたがL2キャシュが128kBと小さいためか、或はSDRAMの実行性能が100MHz程度のようであり、SDRAM関係のDDRやDMA、キャシュの初期設定処理を徹底的に突き詰めた。しかし、改善せず断念した。レイトレーシングでなければラインや円形、塗り潰し等の表示はSPI-LCDよりは800 x 480 解像度表示・ループ500回で約0.2~0.5秒以内と格段に早いので使用できる。2023.05.01
※-9 : LicheePi Nanoは320 x 240ピクセル表示で 2.14sec. とLicheePi Zeroと同程度であり、LicheePi Zeroの Neon-FPU が他のARM SoC と相違があるのか不明です。2026.02.13
※-10 : RX72Tは320 x 240ピクセル表示で 0.99sec. と SPI-LCD タイプよりも 8ビット・バスタイプ( Data 信号 Bus 接続ではなく8bits-Portに Data-Write)が早いが、ILI9386 のドライバーIC がコマンドとデータの切替えが必要なため、 CD ポートを頻繁にポート Hi/Lo 切替えが必要であり8ビット・バス接続しても早くならない。 CD 信号がないTTL レベルRGB565タイプのLCDを利用する必要がある。2026.02.13
PC Python->   RayTracing RayTracing
JavaScript(V8 Engine)のWebGLはPython(Numpyラブラリー)よりもRayTracingが約70倍と高性能であり、V8エンジンがGPUに実行コードを効率よく最適化している。 2022.08.23 更新2025.10.12
| MPU & MCU |
クロック |
解像度 |
ベンチマーク |
備 考 |
| iMac Intel Core i 5 Quad(2010) |
2.8GHz |
800x800 |
0.016 sec. 60FPs(JavaScript) |
GPU FP32 1.0TFLOPs |
| iMac Intel Core i 5-2400S Quad |
2.5GHz |
800x800 |
0.034 sec. 29FPs(JavaScript) |
GPU FP32 570GFLOPs |
| MacBookPro Core i 5-2145M Quad |
2.3GHz |
800x800 |
0.14 sec. 7FPs(JavaScript) |
GPU FP32 380GFLOPs |
| MacBookAir Core i 7-2677M Quad |
1.8GHz |
800x800 |
0.11 sec. 9FPs(JavaScript) |
GPU FP32 380GFLOPs |
| Cortex-X1x2,A78x2, A55x4 (GPU G78) |
2.8GHz |
512x512 |
0.019 sec. 52FPs(JavaScript) |
GPU FP32 1.0TFLOPs |
| Cortex-A78x2, A55x6 (GPU Adreno619) |
2.2GHz |
512x512 |
0.038 sec. 26FPs(JavaScript) |
GPU FP32 536GFLOPs |
| Cortex-A78x2, A53x6 (GPU Adreno619) |
2.2GHz |
800x800 |
0.083 sec. 12FPs(JavaScript) |
GPU FP32 536GFLOPs |
| Cortex-A76x2, A55x6 (GPU Adreno630) |
2.6GHz |
512x512 |
0.071 sec. 14FPs(JavaScript) |
GPU FP32 730GFLOPs |
| Cortex-A76x2, A55x6 (GPU Adreno630) |
2.6GHz |
800x800 |
0.166 sec. 6FPs(JavaScript) |
GPU FP32 730GFLOPs |
| Cortex-A73x4, A53x4 (GPU G72) |
2.0GHz |
512x512 |
0.067 sec. 15FPs(JavaScript) |
GPU FP32 90GFLOPs |
| Cortex-A73x4, A53x4 (GPU G72) |
2.0GHz |
800x800 |
0.14 sec. 7FPs(JavaScript) |
GPU FP32 90GFLOPs |
| Cortex-A55x8 (GPU G57) |
1.8GHz |
800x800 |
0.11 sec. 9FPs(JavaScript) |
GPU FP32 80GFLOPs |
| Cortex-A55x8 (GPU G57) ※-4 |
1.8GHz |
512x512 |
0.052 sec. 19FPs(JavaScript) |
GPU FP32 80GFLOPs |
| Cortex-A53x4 (GPU G52) |
2.0GHz |
512x512 |
0.076 sec. 13FPs(JavaScript) |
GPU FP32 50GFLOPs |
| Cortex-A53x4 (GPU G52) |
2.0GHz |
800x800 |
0.2 sec. 5FPs(JavaScript) |
GPU FP32 50GFLOPs |
| Cortex-A53x4 (GPU T720) |
1.3GHz |
512x512 |
0.5 sec. 2FPs(JavaScript) |
GPU FP32 20GFLOPs |
| iMac Intel Core 2 Duo(2008) |
2.8GHz |
800x800 |
0.14 sec. 7FPs(JavaScript) |
GPU FP32 140GFLOPs |
| Atom-Z3745x4 (GPU GT1) |
1.3GHz |
512x512 |
1.0 sec. 1FPs(JavaScript)※-2 |
GPU FP32 40GFLOPs |
| NotePC Core2 Duo T7700 |
2.4GHz |
512x512 |
0.33 sec. 3FPs(JavaScript) |
NonGPU |
| NotePC Core2 Duo T7700 |
2.4GHz |
800x800 |
1.0 sec. 1FPs(JavaScript) |
NonGPU |
| MacBookAir Core2 (GPU 320M) |
1.6GHz |
512x512 |
0.07 sec. 14FPs(JavaScript) |
GPU FP32 90GFLOPs |
| MacBookAir Core2 (GPU 320M) |
1.6GHz |
800x800 |
0.14 sec. 7FPs(JavaScript) |
GPU FP32 90GFLOPs |
| MacBookAir i5 (GPU HD3000) |
1.6GHz |
512x512 |
0.04 sec. 25FPs(JavaScript) |
GPU FP32 240GFLOPs |
| MacBookAir i5 (GPU HD3000) |
1.6GHz |
800x800 |
0.10 sec. 10FPs(JavaScript) |
GPU FP32 240GFLOPs |
| Orange Pi Zero 2 (GPU G31) |
1.5GHz |
512x512 |
0.33 sec. 3FPs(JavaScript) |
GPU FP32 21GFLOPs |
| Orange Pi Zero 2 (GPU G31) ※-3 |
1.5GHz |
256x256 |
0.1 sec. 10FPs(JavaScript) |
GPU FP32 21GFLOPs |
ChromeBook A72 x 2, A53 x 2
(GPU VR-GX6250) |
1.7GHz |
512x512 |
0.041 sec. 24FPs(JavaScript) |
GPU FP32 57GFLOPs |
ChromeBook A72 x 2, A53 x 4
(GPU Mali-T864) |
2.0GHz |
512x512 |
0.037 sec. 27FPs(JavaScript) |
GPU FP32 95GFLOPs |
PC WebGL->   RayTracing RayTracing
JavaScriptのWebGLはV8 EngineによるGPUの最適化あり。※-2はV8 Engine未対応? 2022.08.23
iMac Core i5のGPUはFP32で1.0TFLOPsと高性能、G72はFP32で90GFLOPs , T720は20GFLOPs 2022.08.23
ディスクトップ・タイプPCのGPUが高性能であるが、GPU単体で消費電力TDP 65W、ARM系がCPU+GPUで10W以下。2022.09.07
最新のARM系GPUも高性能となり1.0TFLOPs~4.0TFLOPsとノートPCと同等、Windows PCが不要な時代となった。2022.09.07
※-4 格安な中国製タブレットtPad(Teclast)はAllwinner-A523(プロセス製造22nm)SoCであり高性能とは言えないが、GPUがMali-G57MC1でありCPUが非力でもGPU性能FP32 80GFLOPsであるためネット・アクセスでも表示のもたつきがなく、ブラウザで音声認識入力ができてWindowsタブレットよりも格段に使い易く1万円程度のタブレットしてはよい製品です。2023.11.06
アマゾンのfire HDタブレットも低価格で品質もよいが、ブラウザで音声認識入力ができずGoogleのソフト関係を面倒な操作でGoogleにユーザー登録しインストールする必要があり、格安な中国製タブレットでもよさそうです。
TeclastのタブレットはUnisocのT606-SoC やMediatek MT6762-SoCタイプもあり多数の格安タブレットを販売しており、低価格でない国産製のタブレットは激安中国製タブレットとの価格競争で厳しい状況です。2023.11.06
格安なスマートフォンAndroid(SoC・Snapdragon 845)はRayTracing球1個アニメーション表示(800x800ピクセル/93FPS)で Core i5 2.8GHzよりも約1.6倍高性能であり、Snapdragon 695でも800x800ピクセル/60FPSであった。2万円以下の格安なスマホも低価格Windowsノート PCと同等な性能となった。2023.06.24
最新のAmazonタブレット Fife MAX 11も高性能となりSoC・MT8188J, CPU Cortex-A78 2.0GHz, GPUがG57MC2/950MHzであり、その性能がFP32・243GFLOPs、GeekBench 5.0/Single 695, Multi 1,870と低価格ノートPCと同等、Windows Note PCが不要な時代となった。しかし、価格が約3万5千円、出費が痛い・・・、2万円台であったなら、残念。2023.06.23
低価格な1万円以下のFire HD 8 (A53 Quad, 2.0GHz)等でも十分な性能であり利用価値がある。ヘビーで遅いOSを使用する気にならない。最近、低価格なAndroidやクロームブック(Chrome OS Book)は軽量なOS(オーエス・基本ソフト)でありキビキビと動作し操作に違和感がない。 2022.08.23
WindowsノートPCではGPUを搭載していないPCもあり、Apple Macと比較するとかなり低速である。NotePC Core2 Duo T7700 (2.4GHz)はMacBookAir Core2(1.8GHz)+GPU(GeFore 320M) よりも約1/5の性能であった。やはり、GPUの性能が汎用CPUコアよりも格段に高性能である。 2022.10.03
Windows10(Atom Z3745)1.3GHzはGPUを搭載しているが、そのGPUの性能が低いか、ブラウザがGPUに最適化していないようである。Atomのタブレットは性能が低いと不評であり、アンドロイド・タブレットのほうが格段に体感速度が高い。 2022.10.03
※-3 中国製Orange Pi Zero 2ボードは価格2,300円程度と激安であり、低価格ノートPCよりも約10分の1以下の価格だから驚きです。仕様はCortex-A53 Quad 1.5GHz, GPU Mali-G31, LCD-I/F HDMI, Allwinner H616 SoC , ボード・サイズ 60 x 52mmと小型です。その性能は高性能とは言えないがインテルAtomコアよりも高性能であり、Linux系のUbuntu-18.04動作の鈍さも少なく充分使用できる。無線LAN・WiFi の接続と設定も面倒ではなく簡単であり、BluetoothやUSBの設定・接続も簡単であった。 2023.10.21
遂に、中国でもSMIC社がARMコア・7nmプロセス製造で製品化しており、中国に対する米国の半導体経済制裁が無意味であったようです。6nm以下のプロセス製造も可能となったようであり、低価格な14nmプロセス製造のARMコアSoCの製品も発売されている。国内ではルネサス社が22nmプロセス製造を1023年春頃から開始しており中国に負けないよう期待します。 2023.10.21
MCUではTFT-LCD との接続がシリアル通信SPIであり、且つ、TFT LCD内部ドライバーICの処理が遅く、その処理時間(0.5~2sec程度)となるので単純な比較ができない。タブレットでは320x240ピクセルの低解像度データを瞬時(約10~20ms)に転送してしまう。
近年のMCUは高性能となり、数百MHzの動作周波数でも 1GHzのプロッセッサに迫る性能となっている。
約10年前のIntel系CPUでは予想外に低性能であり、ARM系のプロッセッサよりもクロックに対し低い性能であった。
最近のPC関係ではグラフィカル・ユーザー・インターフェースAPIが重くなる傾向であり、そのAPI処理にCPU性能が食われてしまうので実体感速度が遅くなる。もちろん、マルチ・コアやSIMD & GPUに最適化すれば高性能となる。
但し、一般的なアプリの制作・プログラミングではマルチ・コアやSIMD(NEON,SSE) & GPUに最適化することが簡単ではなく、難易度が高い。
Pythonでは計算処理が遅く使い物になるとは思えない。但し、Android系のjavaではAPIをGPUに最適化してある為、OpenGLアプリをjavaでコーディングしてもPC関係よりも高性能に感じる。
ARM系のCortex-A73-2.0GHzのタブレットであれば低消費電力で充分な性能であり、ノートPCが必要ないとも言える。
iMac (2010) Core i5-760 2.8~3.33MHzはMandelベンチマーク・テスト時にはCPU温度が48℃から61℃(室温16℃)であった。 室温26℃時にはCPU温度が71℃程度となるであろう。
最新のi9-9980H 8コア 2.4~5.0GHz(ブート)は最高5.0GHzであるが使用時にはコア温度が1分程度で100℃をオーバーしてしまうので実用的でない。最高5.0GHzはスペック上の性能であり意味がなく、実用的な性能が2.5GHz程度でも80℃程度にもなる。また、消費電力がノートPC自体で100Whに達する。
ルネサス社はMCUコアにRISC-Vコアを採用すると発表した。H8 & R8, M16, M32コアからRXコアへ、SH2 & SH4コアからRH850コアへ移行し、ARMコアも追加して更にRISC-Vコアを追加することになり、コアの種類が多い半導体製造メーカーが少ないと思う。
▼ CPUの浮動小数点演算ベンチマーク・テスト 2014.11.02 作成 2023.01.16 更新
シングルコアCPUとマルチコアCPUや組み込み関係MCUのウェットストーン(Whetstone)浮動小数点演算ベンチマーク・テストを実施し,下記に結果を表に纏めました。
| CPUタイプ |
コア数
|
動作周波数
|
GPU
FPU
SIMD
|
whetstone
(MWIPs)
|
OS & Android / Linux /
コンパイラー & Option set
|
備考 |
Snadragon 800
MSM8974AB
|
Quad |
2.3GHz |
GPU |
1T : 1722
2T: 3720
4T: 7244
|
Andriod-4.4.2
Linux-3.4.0
MP-Whetで計測
|
スマートフォン
SHL25
|
| Cortex-A7 |
Quad |
1.2GHz |
GPU |
1T : 760
2T: 1512
4T: 3026
|
Andriod-4.2.2
Linux-3.3.0
MP-Whetで計測
|
タブレットPC
|
| Cortex-A9 |
Dual |
1.4GHz |
GPU |
1T : 1030
2T: 1953
|
MP-Whetで計測
|
Mini PC
|
Snadragon S1
|
Single |
1.0GHz |
GPU |
528 |
Andriod-2.2.1
Linux-2.6.32
|
スマフォ
IS03
|
| Cortex-A8 |
Single |
1.0GHz |
GPU |
526 |
gcc-4.6.3
-O3 -mfpu=neno
|
BeagleBoneBlack |
| Cortex-A8 |
Single |
1.2GHz |
GPU |
307 |
Andriod-4.0.4
Native-Whetで計測
|
タブレットPC
|
| Cortex-A8 |
Single |
1.2GHz |
GPU |
136 |
Andriod-4.0.4
java-Whetで計測
|
タブレットPC
|
| ARM11 |
Single |
700MHz |
FPU |
270 |
gcc
-O4 -mfpu=vfp
|
Respberry Pi
他サイトより引用
|
| ARM926 |
Single |
800MHz |
FPU |
31 |
gcc
|
他サイトより引用
|
PPC-970MP
(PowerPC G5)
|
Quad |
2.5GHz |
FPU
Altivec
|
4T : 14616
※-3 |
MacOSX10.5 gcc-4.0
-O3 -mcpu=G5 -pthread 以降省略
|
PowerMac G5
SIMD最適化なし
|
MPC-7447
(PowerPC G4)
|
Single |
1.67GHz |
FPU
Altivec
|
1818
※-3 |
MacOSX10.4
gcc-4.4 -O2 以降省略
|
PowerBook G4
SIMD最適化なし
|
MPC-7447
(PowerPC G4)
|
Single |
867MHz |
FPU
Altivec
|
952
※-3 |
Ubuntu-10.04
gcc-4.4 -O2 以降省略
|
PowerBook G4
SIMD最適化なし
|
| PPC-440 |
Single |
400MHz |
FPU |
477 |
gcc-4.1.1 -O3
|
他サイトより引用
|
| Core2 Duo |
Dual |
2.4GHz |
FPU
SSE
|
1T : 2316
2T: 4270
|
Windows-XP
MP-Whetで計測
|
SIMD最適化あり
( SSE )
|
| Atom |
Single |
1.66GHz |
FPU |
822 |
?
|
他サイトより引用
|
| SuperH SH-4A |
Single |
266MHz |
FPU |
330 ※-2 |
gcc-4.6.3 -O2 -m4
|
SH7730 Board
|
| SuperH SH-2A |
Single |
266MHz |
FPU |
294 |
gcc-4.6.3 -O2 -m2a
|
|
| SuperH SH-2A |
Single |
144MHz |
FPU |
160 |
gcc-4.6.3 -O2 -m2a
|
|
| RX62N |
Single |
100MHz |
FPU |
130 |
gcc-4.6.3 -O2
|
RXv1
|
| RX71M |
Single |
192MHz |
FPU |
333 |
gcc-4.7.4 -O2
|
|
| RX71M |
Single |
192MHz |
FPU |
461 |
gcc-8.3.0 -O2
|
RXv2
|
| RX66T |
Single |
160MHz |
FPU |
416 |
binutils-2.36, gcc-8.3.0 -O2
|
RXv3
|
| RX231 |
Single |
48MHz |
FPU |
125 ※-4 |
binutils-2.35, gcc-4.7.4 -O2
|
RXv2
|
| H8SX |
Single |
48MHz |
- |
0.88 |
gcc-4.6.3 -O2 -msx -mint32
|
|
| Cortex-M3 |
Single |
100MHz |
- |
1.69 ※-1 |
gcc-4.6 -O3
|
|
| ATmega |
Single |
16MHz |
- |
0.07 ※-1 |
avr-gcc-4.1 -O3
|
|
| PIC24 |
Single |
20MHz |
- |
0.13 ※-1 |
ccs
|
|
| RISC-V(E907) |
Single |
1.0GHz |
DSP ? |
2,610 ? |
gcc- ?
|
他サイトより引用
|
※-1 : 計算式が一桁誤っていたので再テスト実施結果 2014.12.29
※-2 : gccはSH4Aコアに最適化が不充分であるようであり本来の性能となっていない。 2015.01.03
( 純正コンパイラー用MathライブラリーはgccのMathライブラリーと比べ数倍高性能 )
※-3 : PowerPC G4 & G5 のAltiVec ( SIMD ) には最適化していなので最適化すればもっと高性能となる。 2015.03.01
※-4 : RX231はMathライブラリーを独自に最適化した結果、48MHzとしてはSH2/120MHz相当の性能だ。 2023.01.16
注釈 : マルチスレッド数は 1T->1 Threads, 2T->2 Threads, 4T->4 Threads
RX231はルネサス社が演算処理性能を向上させたと発表しており、Mathライブラリを独自に最適化した結果、格段に計算処理性能が向上した。gccのlibm.aや他のmathライブラリはRXコアに最適化が不充分である。2023.01.16
gcc-8.3.0がRXv2&RXv3コアに最適化したようであり、RX71Mの計算処理性能が向上した。
RX66TはRXv3コアであり処理性能が向上している。2022.02.15
WhetStoneで浮動小数点演算ベンチマーク・テストを実施した結果、意外な結果であった。10年前(2005年)のPowerPC G4が意外に良い結果であり充分通用する性能であった。
ラズベリーパイのCPUコアはARM11コア(ARMv6)であるので古いアーキテクチャーと言える,クロックの割りには低性能であった。
組み込み関係のSuperH SH2A/266MHzは294MWIPsと以外によい数値であり,Raspberry Pi/700MHz 270MWIPSよりも高性能である。SH-2Aは低クロックの割にはSH-4の高性能なFPU技術を取り入れているようであり画像処理でも充分通用する。
最新のクアルコム社製Ouad Core 2.3GHzは高性能であり,Linuxカーネルのマルチスレッド処理の最適化も相まって良い結果となっている。
PIC24やATmega ,Cortex-M3はFPUがないため,比較することが酷なことでもあり,浮動小数点演算をソフトで処理しなければならず当然低性能となる。画像処理や化学技術的計算処理、フィルター計算処理等では極端に低性能となるので向かないプロセッサと言える。
10年前(2005年)のPowerMacG5 PowerPC G5 Quad Core 2.5GHzが14,616MWIPsとCore2 Duo 2.4GHzよりも約3.4倍高性能であり今でも充分通用する性能であった。当時としては最速の同時命令実行数5個であり、FPU x 2個とAltivec(SIMD) x 1個に最適化すればもっと高い性能の数値をたたき出せるであろう。ベンチマークテスト時には4個のCPUメーターが同時に振れてマルチ・スレッド処理で並列処理となっている。
他のサイトではPowerPC-970MPの gcc optionが -O3 -mcpu=G5 で動作しない等の間違った情報を掲載しているが、そのようなことがなく正常に動作する。 2015.03.01 追記
次回はSIMDやNVIDIA GPUで浮動小数点演算ベンチマーク・テストのプログラムを制作しテストを実施する予定です。
◆ CPU コアのパイプライン数がなぜ増えない 2020.09.12 作成、2022.06.20 更新
近年のプロセッサのパイプライン(Pipeline)数やスーバースカラー(スーパースケラーSuperScalar)数、Decode数がなぜ増えないのでしょう、限界なのか、SIMDやGPUの性能を向上へ向かっている。
組み込み関係のMCUではパイプラインとスーバースカラーを実装し数百MHzで高性能なMCUがある。下記にMPU & MCUのパイプラインとスーバースカラーを比較した。
| MPU & MCU |
パイプライン(stage)数 |
スーバースカラー & uOP |
| ARM Cortex-M3 & M4 |
3 ステージ |
1 命令同時実行 |
| ARM Cortex-M7 |
6 ステージ |
2 命令同時実行 |
| RXv3 ( RX72N, RX66T ... ) |
5 ステージ |
2 命令同時実行 |
| SH2A |
5 ステージ |
2 命令同時実行 |
| RZ/Fize RISC-V(AX45) |
8 ステージ |
2 命令同時実行 ? |
| RAシリーズのCoretx-M85 |
7~10 ステージ |
2 命令同時実行 ? |
| PIC32 ( MIPS系 M4k ) |
5 ステージ |
1 命令同時実行 |
| RISC-V XuanTie E906(RV64GC) |
5 ステージ |
? 命令同時実行 |
| RISC-V XuanTie E907(RV32IMA) |
5 ステージ |
? 命令同時実行 |
| RISC-V XuanTie C910 (RV64GC) |
12 ステージ |
3 命令同時実行 ? |
| RISC-V XT-910 (RV64GCV) |
7 ステージ |
8 命令同時実行 |
| D1s/F133 RISC-V(C906) |
5 ステージ |
? 命令同時実行 |
| P550 RISC-V(RV64GC) |
13 ステージ |
? 命令同時実行 |
| P8700 RISC-V(RV64GHC) |
16 ステージ |
Decode 8 命令同時実行 |
| Nvidia Armv8.2 Carnel |
? ステージ 7 way ? |
10 wide Scalar 命令同時実行 ? |
| ARM11 ( ARMv6) |
8 ステージ |
? 命令同時実行 |
| ARM Cortex-A7 ( ARMv7) |
8~10 ステージ |
2 命令同時実行 |
| ARM Cortex-A8 ( ARMv7) |
13 ステージ |
2 命令同時実行 |
| ARM Cortex-A9 ( ARMv7) |
9~12 ステージ |
2 命令同時実行 |
| ARM Cortex-A53 |
8 ステージ |
2 命令同時実行 |
| ARM Cortex-A57 |
15+ ステージ |
3 命令同時実行(Decode) |
| ARM Cortex-A15 |
15 ステージ |
2 命令同時実行 |
| ARM Cortex-A72 ( ARMv8-A) |
15+ ステージ |
3 命令同時実行 |
| ARM Cortex-A78 ( ARMv8.2-A) |
13 ステージ |
uOPs 6 命令同時実行 |
| ARM Cortex-A710 ( ARMv9-A) |
13 ステージ |
uOPs 8 命令同時実行 |
| PowerPC-7457(G4) |
7 ステージ |
4 命令同時実行 |
| PowerPC-970(G5) |
16~23 ステージ |
5 命令同時実行 |
| Intel Pentium-4 |
20 ステージ |
3 命令同時実行 |
| Intel Core2 |
14 ステージ |
3 命令同時実行 |
| Intel Core i5 & i7 |
14~19 ステージ |
4~6 命令同時実行 |
| Apple A14 & M1 |
12 ステージ ? |
Decode 8 命令同時実行 |
Intel社製のPentium-4は20段のパイプラインであったが、Pentium-3の11段と比較し格段な性能向上にならなかった。
PowerPCは20年前にスーバースカラーが5 命令同時実行であったが、ARM系やIntel系では5~10年遅れで5 命令同時実行が可能となった。
ARM系Cortex-M7はCortex-M4に対し大幅に性能向上となっており、組み込み関係のMCUでも約30年前のWindows95時代のCPU性能を追い越している。
ルネサス社のRXコアはスーパースカラーを実装しRXv1に対しRXv3が約3倍もの性能向上となっている。
組み込みではPCやスマホのような重たい画像処理が少なく、消費電力が大きいSIMDやGPUを実装する必要性がないのでスーパースカラー数を増やすべきであろう。
PCやスマホ用のプロセッサはマルチ・コアが主流でありコア毎にキャシュ・メモリを実装しないと性能向上とならない。そのキャシュ・メモリが半導体の面積を占有してしまい、消費電力が大きくなる要因ともなっている。また、クロック・アップの阻害要因ともなっている。
マルチ・コア構成ではDualとQuadコアの実性能差が1.5~1.6倍程度であり、体感的にも性能の向上が感じられない。コア数を増やしてもコア数の倍とならず消費電力が増えるだけである。但し、GPUの性能向上はかなり体感差があり、CPU性能よりもGPUの性能を上げることが重要なのであろう。
▼ マイコンMCU & MPUのドライストーン(DhryStone)性能 2022.05.08 作成、2023.04.16 更新
マイコンMCUの性能ベンチマークテスト比較は種々あるが、DhryStoneが実性能に近いようである。
下記にMCU &MPUのドライストーン(DhryStone)性能比較を纏めました。
| MCU &MPU |
コア |
DhryStone(DMIPs) |
動作周波数 |
備考 |
| R-Car V3U |
Cortex-A76 x 8 |
96,000 |
1.8GHz ? |
ルネサス社製 |
| RZ/G1M,G1N |
Cortex-A15 x 2 |
10,500 |
1.5GHz |
ルネサス社製 |
| RZ/G1C |
Cortex-A7 x 2 |
3,800 |
1.0GHz |
ルネサス社製 |
| RZ/Five |
RISC-V(AX45) |
3,140 |
1.0GHz |
ルネサス社製 |
| R9A06 ※-9 |
RISC-V(DF25F) |
198 |
100MHz |
ルネサス社製 |
| RA シリーズ※-3 |
Cortex-M85 |
3,130 |
1.0GHz |
ルネサス社製 |
| RX72N |
RXv3 |
696 |
240MHz |
ルネサス社製 |
| RX66T |
RXv3 |
464 |
160MHz |
ルネサス社製 |
| H8SX/1700 |
H8 |
89 |
80MHz |
ルネサス社製 |
| F1C100S,200S |
ARM926ES-J |
712 |
Max.900MHz |
Allwinner |
| RaspberryPi-Zero |
ARM1176ZF-S |
697~870 |
700MHz |
BCM2835 |
| RaspberryPi-2 |
Cortex-A7 x 4 |
1,670 |
900MHz |
BCM8327 |
| ESP32-S2 |
Xtensa-LX6 |
142~237 |
240MHz |
Dual-CPU Core |
| K210 |
RISC-V(RV64GC) |
410 |
400MHz |
Dual-CPU Core |
| PIC24 |
PIC |
16 |
32MHz |
MicroChip |
| Teensy3.2 |
Cortex-M4 |
91 |
72MHz |
|
| iMX RT1170-1176 |
Cortex-M7 |
2,970 |
1.0GHz |
|
| RA6M4 |
Cortex-M33 |
300 |
200MHz |
ルネサス社製 |
| D1s(F133) |
RISC-V(C906) |
2,400 |
1.0GHz |
Allwinner |
| CH2601 |
RISC-V(E906) |
530 ? |
220MHz |
Alibaba |
| T310 |
A75 x 1,A55 x 3 |
13,600 ? ※-5 |
2.0GHz |
Unisoc スマホ |
| RISC-V |
RV32IMA(E907) |
2,000 |
1.0GHz |
XuanTie |
| T-Head ※-7 |
RV64GC(C910) |
2,880 ?(コア x1個) |
1.2GHz |
XuanTie(Alibaba) |
| XuanTie-910 ※-8 |
RV64GCV |
6,000 ?(コア x1個) |
2.5GHz |
XuanTie(Alibaba) |
| P550 |
RV64GC(7nm) |
15,800 ? |
2.4GHz |
スマホ(MIPS社) |
| P650 |
RV64GC ?(5nm) |
24,840 ? |
2.7GHz |
スマホ(MIPS社) |
| MT8183 |
Cortex-A73(Octa) |
12,600(A73 x1個) |
2.0GHz |
MediaTek ※-5 |
| MT8163 |
Cortex-A7(Quad) |
307(Java)※-6 |
1.3GHz |
MediaTek |
| T4240(12core) |
e6500(PowerPC) |
153,600 |
1.8GHHz |
NXP ※-1 |
| Core i7-4750HQ |
x86-64 Quad Core |
23,940 |
2.0GHHz |
Intel ※-2 |
※-1 : PowerPC・T4240のCoreMark性能 187,873(2012年度)、プロセス製造28nm、スレッド数 24
※-2 : Core i7-4750HQは2013年でプロセス製造22nm、消費電力47Wと高性能ではない。
※-3 : 2023年リリース予定。
※-5 : コア1個当りの性能、MT8183はコアA73x4 + A53x4 -> 43,000DMIPs程度
※-6 : Android-5.0のJavaでの計測、gccでコンパイルすれば2.900DMIPs程度
※-7 : AlibabaのT-HeadはDual コア + GPU + NPU構成 12nmプロセス製造 、SipeedのRVB-ICEボードAndroid-10動作
※-8 : AlibabaのXuanTie-910は16コア2.5MHz、性能はSpnapdragon-663相当、Android-10スマホ動作
※-9 : ルネサス社がRISC-Vコアの小ピン小型マイコンR9A06G150を発表した。
Coremark性能は約10年前(2012年)にPowerPC(e6500タイプ・コア)がApple M1/3.2GHzの162,568よりも消費電力的に高性能であった。e6500タイプ・コアはプロセス製造28nmであり3~7nmプロセス製造であれば更に高性能となったであろう。但し、Apple M1はGPUが高性能であり、T4240にはGPUがないので単純な比較ができない。
RXv3コアも16nm程度のプロセス製造であれば更なる高性能となるのでルネサス社に期待したい。また、中国製のARM系のようにSDRAMをSiP構造とすればHMI等のタッチパネルLCDへの利用が可能となる。
現状のRXv3ではRAMメモリ容量が小さく解像度800x480以上のTFT・LCDを接続できない。拡張バスでSDRAMを接続しないワンチップMCU+SDRAMのSoCとSiP構成がよい、BGAパッケージではなくQFPがよい。2022.06.07
ARM系コアには人工知能処理用NPU搭載のCortex-M55とCortex-M85があるが、このコアのMCU製品が発表されない、大変残念・・・。
Cortex-M85コアのRAシリーズが5月末に製品化され待望のQFPパッケージで2023年に発売となる。2022.06.07
中国のアリハバ(Alibaba)やMIPS社ではRISC-Vコアの開発を進めており、国内メーカーではRISC-Vコアの開発が遅れており大変残念である。RISC-Vコアのデバイス・チップの開発はAppleやIntel社、他のメーカーも進めようとしている。遂にスマーフォンもRISC-Vコアとなり低価格スマホが普及するのであろう。2022.06.11
開発ソフト言語のC++,Clang,Java,NodeJs,Lua,Kotlin,Python,PyPy,MicroPyhton,Clang,TinyBasic等、及びコアマーク(Coremark)のベッチマークは下記のページ。
C++,Clang,Java,Pythonのベンチマーク・テストはこちらのページ
LinuxカーネルではマルチCPUコアやGPUに最適化が進み、重いAPIと体感速度が遅い汎用OSよりもキビキビ動作するLinuxのほうがよい。2022.10.03
軽量で軽快な動作のPuppyLinuxのページ
▼ 理解し易いCPUの基礎的なページ。
進化する多機能・高性能で低価格な組込み用マイクロ・プロセッサMPU関係のページはこちらです。
本ページの複写禁止、他サイト・ページへの転写を禁止します。 作成 2014.11.02
|
|
|